I think it was July 1994--I was conversing by phone with a west-coast colleague who asked, “Have you heard about the web?” Mentally, I dropped the “the” in the question, and interpreted “web” as WEB. “Yes,” I said, “I have read Knuth’s article.”[1] This reply made no sense to my interrogator.
Of course I do not recall his exact words twenty years later but my colleague informed me he was referring to an invention of Tim Berners Lee, not Donald Knuth.[2] That was the first I had heard of the world wide web.
What then was the other WEB? In his article Literate Programming, originally published in The Computer Journal (May 1984) and reproduced in a same-titled book,[1] Knuth explained the idea that led to WEB. “Let us change our traditional attitude to the construction of programs. Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.” The WEB system that Knuth conceived in order to make essayists of programmers combined his document formatting language TeX with a computer programming language (Pascal). I will not attempt to explain WEB here--More about the system can be found in Knuth’s article or book.
The MUMPS programming language[3] (also called M) lies at the antipode of WEB. Although it is surely possible to program literately in any language, MUMPS invites obscurity, or at least terseness, more so than most other programming languages. Commands are usually abbreviated to single letters. Intrinsic function names are also typically abbreviated. More than one MUMPS programmer has delighted in the discovery that the character sequence x x x is meaningful in MUMPS, where the first x is a line label, the second an abbreviation for the xecute command, and the third a variable containing MUMPS code to be executed.
I once knew a MUMPS programmer who expressed inordinate fondness for the letter “q.” Q is the abbreviaton for the quit command in MUMPS (similar to the return statement in better known languages). $Quit is a related intrinsic function. And of course, q can name a variable. Thus, the sequence q:$q q is meaningful, “Quit (return), if an argumented quit is required (in other words, if called as an extrinsic function), returning the value q.”
Variables in MUMPS are sparse arrays. Thus the variable q can have subscripts, for example, q(0), q(0,0) or q(q), etc. Strings subscripts are also valid in MUMPS (resembling the hash type in some languages). Thus q("q") is a variable. One could write q:q(q)=q("q"), which would be read: “Quit (or return) if q(q) is equal to q("q").” I present this rather silly example just to show how easy it is to generate perversely tedious-to-read code in MUMPS. Viewing line after line of the letter q with an occasional smattering of other letters might make one wish for a new lens prescription.
Upon reading about Donald Knuth’s WEB system in the early 1990’s, the idea occurred to me to invert the WEB process, in other words to generate documentation automatically from the terse content of MUMPS programs, using TeX, of course, to format and display the documentation.
The mapping of command and language-intrinsic function names to their abbreviations is one-to-one. Hence it is trivial to convert abbreviations back to full names. Similarly, with a little work one might arrange commands on separate lines, indenting blocks according to the program’s structure, and so forth. But these steps alone would not suffice to convert a MUMPS program into an literate essay. To understand a program, the reader would need to know what the program’s variables represent, the q’s, qq’s, qqq’s and so forth. Similarly, if the program calls external functions or procedures (most programs do), the reader would need to know what those functions or procedures do, and the meaning of their parameters. References to database elements (files, fields, etc.) should also be explained in some descriptive form.
In the spring of 1994 I experimented with these ideas, within a narrowly defined scope, starting with a single line of source code as the object for translation. The documentation application that I developed then consisted of routines (programs) and files, the latter containing descriptions of variables and so forth, the elements of a given application. When the system reached a point of satisfactorily documenting a moderately complex MUMPS program I prepared a description for publication in M Computing, the journal of the now defunct M Technology Association.[4]
My article, published in the September 1994 issue of M Computing[5] bore the somewhat hyperbolic title, “Translating M into English.” I will attempt to refrain from repeating details of the project that may be found in the scanned article. However, recently I located a backup of the application on 3-1/2 inch diskette, dated May 1994. It is impossible to tell at what stage in the development this backup was made. It appeared to have been made near the end, but not at the end of development. The document formatting part (text-to-TeX) was missing. However, I subsequently located a separate backup of one platform-specific version of the TeX formatting part.
An oft-touted virtue of the MUMPS programming language is its portability or platform-independence--MUMPS was an ANSI standard language. Not only is MUMPS portable across operating systems, it is portable across time. In other words it is durable. Upon restoring the 20-year old routines to a 2014 MUMPS platform, the code compiled and ran without error. Since 1994, the language itself has acquired additional features, but in a backward-compatible way.
The exercise of restoring and examining these old routines was frustrating, however, because I could not find a user interface or any sort of wrapper that processed code blocks or whole routines or routine sets. Yet I know that such existed, having found an example of voluminous output for a routine (many pages of generated documentation). Therefore I decided to undertake a mini project, with the initial goal of recreating the missing wrapper. While doing this I should also update the original application to interpret MUMPS language elements that were added to the standard after 1994. Finally, I should test the whole thing using a modern TeX implementation, such as TeX Studio.
** off-line work, user
interface, feature creep, etc. **
Hmm. That took rather longer than expected. The user interface (prompt for code to be analyzed) was straightforward. However, exercising the new interface to test the text-to-TeX formatter with various code examples revealed first one, then another, and then another annoying formatting issue. Some of these may have been addressed 20 years ago--I cannot tell. However, each one compelled some sort of corrective action, to make the test output tolerable to view and read.
I decided that any and all changes should be made conditionally, so that the original code could be run at any time for comparison. Thus, a new application-wide variable was introduced and defined. Each revision was made conditional on that variable’s value. The logic was, “If in the new context, format in the revised way; otherwise format in the original way.”
The first problem was excessive wasted space, not so much due to TeX (although TeX default margins seemed confining) but rather due to unnecessary repetition and superfluous explanations, such as "This is a comment." In the revision, whole-line and multi-line comments are displayed only once.
The second problem--I am nearly sure this one was corrected long ago in a lost revision of the application--was failure to resolve the descriptions of one class of variables in the source. To explain this problem it is necessary first to summarize the data files that make up an essential part of the documentation application. The four files are named Routine Documentation, Kernel Variable, Intrinsic Function, and System Variable. Two of these files are pre-populated with MUMPS language features (intrinsic function names or system variables). The Kernel Variable file applies in the special context of the Department of Veterans Affairs VistA application suite. The Routine Documentation file is the main repository of application level documentation. This file may be used to record descriptions for application-wide variables or for variables whose scope or meaning is routine-specific.
It turned out that the code to interpret scoped variables was entirely missing. The routine where it should have been found had a comment, “Insert routine-specific lookup here.” So I inserted it. The process of constructing “good” variable descriptions is iterative. First, one tries a description (shorter is better). Then after running the application and reading the description in context, improvements of wording more or less suggest themselves.
Vertical spacing remains imperfect. The problem is that the desired amount of vertical space is not simply a function of the type or class of subject being displayed, but can also relate to the human-meaning of the thing--some contextual attribute that is not distinguishable by its type or place in the code. However, the spacing is not terrible, when it is considered that the application (if it is useful at all) works best for small code excerpts (single lines or circumscribed blocks).
In MUMPS, the “=” symbol doubles as assignment operator as well as comparison operator. However, the application reads “=” as “equals” regardless of context. It would be better if an assigment, S A=B, were read as “Set A equal to B” and a comparson, I A=B, were read “If A is equal to B” or “If A equals B” to distinguish the meanings more clearly. But there is only so much that is worth doing with an old project revisited.
** Examples **
Interpreting a single line of MUMPS code - Later in this page I will include a link to the revised source code. But first I will describe one or two simple examples, to illustrate both positive and negative features of the application. The newly minted user interface routine is AFFC2014, which is entered at tag EN. --This is a terminal-mode application, not a Graphical User Interface.
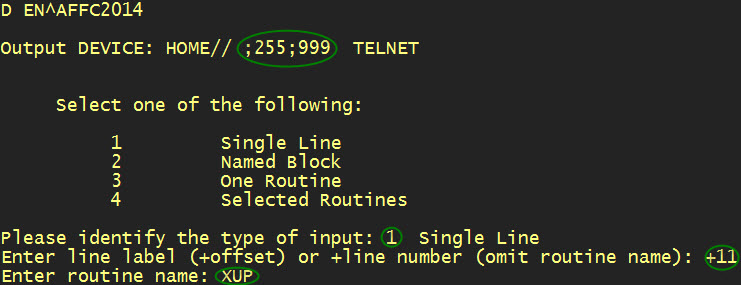
User responses are circled in the illustration. First, we specify a wide margin and long page length because we intend to copy and paste the output, and do not want to introduce superfluous new lines in what may be a verbatim section. Of course, it is possible to specify a host file for output. However, since the input consists of a single line of code, it will be easy to copy and paste output. The routine line to be examined is +11^XUP. And, as is obvious from the illustration, the line is identified first, then the routine.

The illustration above shows the generated TeX output for the single line of source code specified for input. It is highlighted for copying to the clipboard. After copying, the generated code is pasted into TeXstudio (version 2.3). Next we press the button labeled PDF LAT to compile the source and generate PDF (portable document file) format output. The formatted output may then be viewed using the PDF previewer or by opening the PDF file independently of TeXstudio.

In order to display ASCII quotation marks rather than curly quotations, the (revised) generated top matter includes \usepackage[T1]{fontenc}. The font is not as pleasing as the default, but curly quotes are just not okay in the TeX formatted explanatory part (last two lines of the example). Perhaps there is a better way to deal with this requirement.
Italicized descriptions are obtained from the previously mentioned Routine Documentation file. An excerpt from the relevant entry in that file is shown in the following illustration.[6]
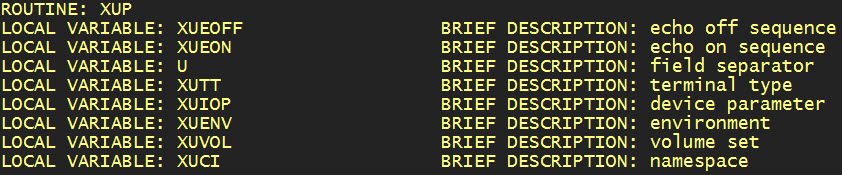
The particular line of code selected for this example contained only one command having multiple arguments. More typically, old style MUMPS source code packed many commands on one line. The application documents each command separately (i.e., as a separate TeX \subsection). As may be imagined, this consumes significant space.
Interpreting a code block - The next example will illustrate interpretation of a code block (function or subroutine). Then I will present some numbers to convey the immensity of the generated documentation for routines or routine sets. While these options exist in the user interface, they are not generally practical.
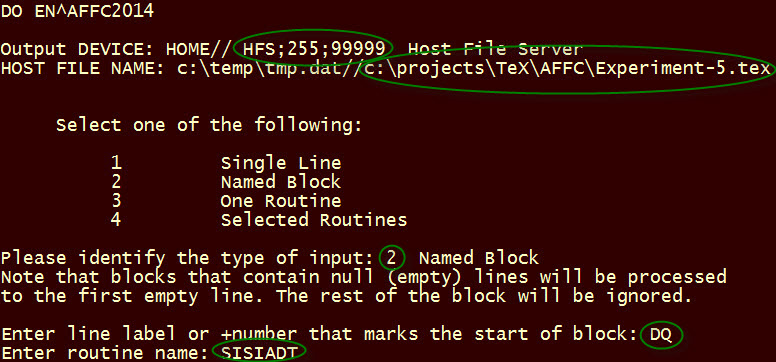
This second example also illustrates writing generated TeX to a host file. The specified code block DQ^SISIADT is short enough (22 lines of MUMPS) to use copy / paste for transferring the output (220 lines of TeX) to TeXstudio. However, for options 3 and 4, it would usually be easier to write output to a file, and then open the file in TeXstudio, as illustrated.
The DQ^SISIADT example produced a five-page report (Experiment-5.pdf). How literate is it? Not very, in my opinion. With every example, one thinks of things that would improve the readability of that example.
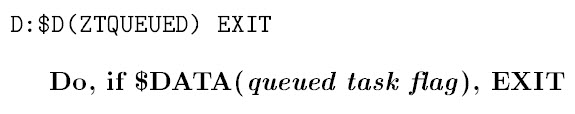
The Intrinsic Function file entry for $DATA has the following -

Note that in this file entry the synonym for $DATA is “defined.” Therefore, shouldn't the intrepretation have read, “Do, if defined(queued task flag), EXIT”...? The 1994 version of the M Code Reader also included a verbose mode, which I have not examined yet. Possibly in this mode synonyms are substituted for intrinsic function names.
Of course, the more verbose the interpretation, the longer the resulting document. On the other hand, humans typically require only one explanation for each new concept. Alas, the mechanical documenter does not respect human intelligence. Each variable is interpreted every time it appears. --Perhaps a “sparse” mode is needed, in which concepts are explained the first time they appear, and presented verbatim thereafter.
The “sparse” idea is sort-of interesting and I may try to do more with it later. In case anybody else wants to have a go at it or at other improvements, the routines are here: Windows format, and Linux format. These files are plain text and can be imported using the ^%RI utilities of GT.M or Caché. After downloading and importing, DO AFFCINIT to create the four Fileman files (Fileman is required). To exercise the routines DO EN^AFFC2014.
Finally, to give an idea of the size of generated output, one test routine (228 lines) produced 2,128 lines of TeX output, which compiled to a 46-page PDF format document. Thus, a rough estimate would be 10:1 for TeX to MUMPS lines, or one page of formatted output per five lines of MUMPS source code.
[1] Donald Knuth. Literate Programming (CSLI Stanford University, 1992). Chapter 4.
[2] History of the World Wide Web (Wikipedia)
[3] http://en.wikipedia.org/wiki/MUMPS
[4] The M Technology Association was the successor to the MUMPS User's Group. Its journal M Computing covered subjects of interest to the MUMPS / M language community.
[5] M Computing, Volume 2, Number 4, 22-27.
[6] The variable U is also defined in the Kernel Variable file, so is superfluous here.